
altri risultati...
Trova le Mostre e gli Eventi nella tua Città | Segnala il tuo Evento

- Questo evento è passato.
Prompt Generations – Exhibition in Virtual Gallery 3d
martedì 20 Dicembre 2022 - martedì 28 Febbraio 2023

sede: Arte.Go.Gallery (Online)
cura: Ennio Bianco, Pier Giorgio De Pinto
L’esposizione Prompt Generations – promossa da Arte.go.it con la curatela di Ennio Bianco e Pier Giorgio De Pinto e la collaborazione di Giorgio De Novellis – vuole inserirsi nel segno del grande cambiamento che riguarda l’arte contemporanea rappresentato da una nuova forma d’arte, che chiameremo Generative AI Art.
Cerchiamo allora di accompagnare lo spettatore definendo subito alcune caratteristiche peculiari di questo nuovo contesto in cui verrà a trovarsi visitando la mostra in modalità virtuale 3D.
Va subito sottolineata la differenza fra l’Arte Concettuale e la Generative AI Art. L’arte concettuale, un movimento artistico emerso negli anni ’60, si basa sull’idea o sul concetto alla base dell’opera, piuttosto che sull’opera d’arte stessa. In altre parole, il concetto o l’idea è più importante dell’opera finale.
La Generative AI Art si riferisce all’arte creata utilizzando algoritmi, programmi per computer e altre tecnologie sviluppate nel campo dell’Intelligenza Artificiale. Questo tipo di arte viene creata addestrando un modello di apprendimento automatico su un ampio set di dati di immagini o altri dati e quindi utilizzando quel modello per generare nuove opere d’arte.
Quindi, in generale, la principale differenza tra l’Arte Concettuale e la Generative Al Art è la fonte delle idee che sta dietro l’arte. L’arte concettuale si basa sulle idee dell’artista, mentre l’arte realizzata con Al si basa sulle idee generate da un modello di apprendimento automatico.
La Generative AI Art può essere considerata una nuova forma di Media distinto dall’Arte Digitale “tradizionale”. Una delle principali differenze è il ruolo dell’artista nel processo di creazione. Nell‘Arte Digitale tradizionale, l’artista ha in genere un alto grado di controllo sull’opera finale, utilizzando strumenti e tecniche digitali per creare l’arte, per esempio codici di programmazione o interfacce grafiche. Al contrario, nella Generative Al Art, l’artista gioca un ruolo più indiretto, fornendo istruzioni o suggerimenti al sistema Al e quindi consentendo al sistema stesso di generare l’opera d’arte attraverso l’utilizzo dei propri algoritmi e processi.
Un’altra importante differenza tra queste due forme d’arte è l’interfaccia utente. L’Arte Digitale tradizionale viene in genere creata utilizzando un’Interfaccia Utente Grafica (GUI), in cui l’artista interagisce con gli strumenti digitali utilizzando un mouse, una tastiera o un altro dispositivo di input. La Generative AI Art, invece utilizza un’Interfaccia Utente Testuale (TUI), in cui l’artista fornisce istruzioni o suggerimenti al sistema Al utilizzando comandi basati su testo. Ciò consente all’artista di interagire con l’IA in modo più flessibile ed espressivo e apre nuove possibilità per creare ed esplorare l’arte.
Nel complesso, l’arte generativa dell’intelligenza artificiale può essere considerata un Nuovo Media che offre opportunità e sfide uniche per gli artisti, combinando il potere dell’intelligenza artificiale con la creatività e l’ingegnosità degli artisti umani, che rimane un elemento fondamentale.
La qualità e l’aspetto estetico delle immagini prodotte da questo Nuovo Media, in concreto dai sistemi come DALL-E 2, Midjourney e Stable Diffusion, e altri, possono variare a seconda di una serie di fattori, i principali dei quali sono: il tipo di modello di apprendimento automatico utilizzato, la qualità e le dimensioni del set di dati e i suggerimenti o le istruzioni fornite ai Modelli AI, i famosi Prompt.
In generale, l’utilizzo di un modello di apprendimento automatico di alta qualità e di un set di dati ampio e diversificato può contribuire a migliorare l’aspetto estetico delle immagini generate da questi sistemi Al. Inoltre, la creazione accurata dei suggerimenti o delle istruzioni fornite all’IA può anche aiutare a guidare il processo di generazione verso la produzione di immagini qualitativamente più rispondenti agli obbiettivi dell’artista.
E’ difficile prevedere esattamente come si evolverà la Generative AI Art e quale impatto avrà sulla società. Tuttavia, è probabile che questa nuova forma d’arte continuerà a guadagnare popolarità e riconoscimento e potrebbe diventare una parte importante del mondo dell’Arte in futuro. Probabilmente potrebbe anche avere implicazioni più ampie e trainare l’uso dell’IA in altri campi, come l’istruzione, l’intrattenimento e la tecnologia.
In conclusione, organizzare una mostra di Generative AI Art dal titolo Prompt Generations, nella galleria virtuale 3D di Arte.go.it, ci è sembrato un progetto affascinante ed eccitante, che permette di mettere in mostra il lavoro di alcuni artisti internazionali più talentuosi e innovativi che da tempo lavorano con questo Nuovo Media, e in questo modo riteniamo di contribuire ad aumentare la consapevolezza e l’apprezzamento per la Generative AI Art, fornendo così agli spettatori un’esperienza unica e coinvolgente.
Con Pier Giorgio De Pinto e la collaborazione di Giorgio De Novellis abbiamo assegnato alla esposizione un titolo forte e coinvolgente, “Prompt Generations“, dal momento che riteniamo sia sufficientemente ambiguo e quindi interpretabile in molteplici modi, con ciò aggiungendo fascino e interesse della mostra. Inoltre, la parola “Prompt” suggerisce che le opere in mostra sono state create in risposta a una sorta di stimolo o ispirazione, ed anche questo potrebbe anche essere un altro aspetto intrigante da esplorare.

Prompt Generations – Exhibition in Virtual Gallery 3d
La mostra online è terminata il 28 Febbraio 2023
Gli artisti
Vladimir Alexeev (aka Merzmensch) (DE, Mosca 1979), può essere considerato come il maggior e più aggiornato esperto degli sviluppi dell’intelligenza artificiale a supporto dell’arte, della letteratura e delle graphic novel. I suoi articoli, sistematicamente pubblicati su Medium ed altri media, sono particolarmente apprezzati per la vastità delle sue esplorazioni delle capacità creative dell’AI e per la chiarezza con la quale commenta le proprie ricerche.
I suoi interessi si rivolgono alle fonti letterarie e partono dalla premessa che DALL-E 2 utilizza il Modello GPT-3, un Modello addestrato sui testi, non solo sulle immagini, quindi ben consapevole dei contesti. Questo consente all’opera “Dreams of Franz Kafka” di recuperare pienamente l’energia narrativa del grande autore praghese, e con essa la collisione tra realtà e assurdità.
Un’altra linea di ricerca è focalizzata nella produzione di immagini per illustrare una storia. Ciò è reso possibile in quanto Midjourney consente di utilizzare, all’interno del prompt, non solo testi, ma anche immagini catturate dal web o dal proprio computer. “Solitamente un illustratore, egli afferma, segue il percorso narrativo di una storia già definita a priori. In questo caso ho co-creato una storia insieme all’IA, senza sapere come si evolverà. La collaborazione creativa uomo-macchina è un’esperienza stimolante!”
-

- Merzmensch – Dreams of Franz Kafka
-

- Merzmensch – Neural Selfie (from: The Big Secret of a Little House)
Alan Bogana (CH, Faido 1979), artista svizzero con residenza a Ginevra, nella sua pratica artistica, che comprende scultura, computer grafica, elettronica, media basati sul tempo e olografia, mette a fuoco il comportamento della luce e delle sue interazioni con la materia. Indaga questo ampio campo di studio attraverso vari mezzi, come simulazioni in computer grafica (dopo il diploma di Belle Arti con lode presso l’Università di Arte e Design di Ginevra si è specializzato in computer grafica e in metodologie di ricerca artistica presso l’Università di Arte e Design di Zurigo) di fenomeni impossibili o la manipolazione di materiali traslucidi, fosforescenti e olografici.
Proprio per la sua forte attenzione per i fenomeni fisici, Alan Bogana è stato chiamato, con l’artista cilena Nicole L’Hullier, al programma di residenza condivisa Simetría, istituito da Arts at CERN e Corporación Chilena de Video, che ha permesso ai due artisti di esplorare la relazione tra astronomia e fisica delle particelle. Dopo questa esperienza Bogana ha realizzato il video-saggio “Ionize, Ionize!”, che prende come punto di partenza le proprietà uniche degli scintillatori, materiali traslucidi che emettono luce quando vengono colpiti da diversi tipi di particelle invisibili. “Ionize, Ionize!” è stato presentato nella mostra Broken Symmetries al Kumu Art Museum (Tallinn).
Per l’Esposizione “Promt Generations” Alan Bogana, presenta delle immagini che hanno origine da un recente lutto famigliare e ad un tenero ricordo d’infanzia, legato ad una buccia essiccata di un mandarino.
Nascono così i “Mandarin Mausoleum #1 e #2” due magnifiche sculture architettoniche collocate in uno spazio metafisico.
-

- Alan Bogana – Mandarin Mausoleum #1
-

- Alan Bogana – Mandarin Mausoleum #2
Julian Bonequi (MX, Mexico City, 1974), si autodefinisce un “Hybrid Artist & XR technologist”. Questa definizione è particolarmente precisa e ben rappresenta un artista che opera ai confini più avanzati del territorio in cui Scienza,Tecnologia e Arte collaborano stimolandosi vicendevolmente e dove gli artisti lavorano in campi come la biologia, la robotica, le scienze fisiche, le Human Interface sperimentali (Mobile, Smatglass, Wearebles, Haptic, Gestures, Voice, Neural, TUI), lo Spatial Computing (3D Engines, VT/AR/XR, Multitasking, Geospatial Mapping, Metaverse), ecc.
Gli Hybrid Artist affrontano la ricerca in molti modi, come intraprendere nuovi programmi di indagine, visualizzare risultati in modi nuovi o criticare le implicazioni sociali della ricerca; sempre con l’idea che ampliare l’orizzonte dell’esperienza consapevole e della conoscenza sia il ruolo fondamentale dell’arte.
Sono sempre stato affascinato dagli Hybrid Artist e dentro di me li ho sempre ritenuti i discendenti dei grandi alchimisti che nel basso Medioevo e nel Rinascimento diedero impulso, fino all’avvento del metodo scientifico galileiano, alle conoscenze nell’ambito della metallurgia, della farmaceutica, oltre che alle discipline filosofiche ed esoteriche.
Nelle due opere presentate per l’Esposizione: “Diving into Reality” e “These Boots Are Made For Walkin” Julian Bonequi si chiede il senso più profondo dell’Intelligenza Artificiale che a suo modo di vedere è quello di creare una Nuova Estetica, non certo quello della finzione virtuale, della speculazione e della creazione di una nuova economia della illusoria speranza per i creatori attraverso la blockchain?
Egli trova che “lo stesso Metaverso non sia empatico e che sia perciò necessaria un’evoluzione del Design ispirata alla Natura, sviluppando soluzioni fattibili e concrete per la Realtà, al di là della speculazione, della digitalità e della virtualità, al fine di ispirare soluzioni sanitarie e di sopravvivenza in grado di permetterci di affrontare cambiamenti climatici indesiderati.”
-

- Julian Bonequi – Diving into Reality
-
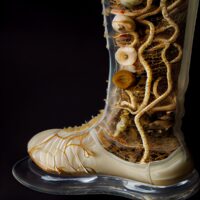
- Julian Bonequi – These Boots Are Made For Walkin’
Marco Cadioli (IT, Milano 1960) è un esponente di primo piano dell’Arte Digitale italiana. Sorretto da una grande curiosità verso le tecnologie digitali emergenti ha percorso quasi tutte le tappe che hanno contrassegnato il dialogo creativo con i Personal Computer, dai Macintosh della Apple alle nuove possibilità offerte dall’Intelligenza Artificiale, come l’utilizzo delle applicazioni che riconoscono i volti e gli oggetti o dei GAN (Generative Adversarial Network).
Proprio per questo suo grande bagaglio di esperienze, la sperimentazione delle applicazioni Text-to-Image è stata per lui affascinante e travolgente. “Sono stato risucchiato in un vortice di immagini, in un flusso di coscienza che scorreva dalla mia mente all’intelligenza artificiale e si materializzava sullo schermo”.
I suoi temi, quelli che in fondo hanno segnato tutto il suo percorso artistico, sono quelli della comprensione dell’impatto che le nuove tecnologie hanno sull’umanità. Una umanità che sta attraversando un periodo di transizione verso il post-antropocentrismo, verso mutazioni le genetiche, cyborg ed eterodirette.
Le due opere che presenta “Portrait of a man who has lost everything” e “Portrait of a King” si collocano proprio in questo contesto. Le didascalie potrebbero indurre lo spettatore a ritenere che immagini si riferiscano alle due polarità in cui l’economia delle diseguaglianze sta trascinando l’umanità: un Re e un Homeless. Lo sguardo percepisce invece in entrambe le figure la stessa ambigua drammaticità, la stessa deformazione dell’aspetto fisico, lo stesso destino, un messaggio molto simile a quello che trasmettevano le Danze Macabre medioevali: Papa, imperatore, re, ecce cc fino all’ultimo contadino, tutti erano accolti con uguale democraticità nella grande ballo.
-

- Marco Cadioli – Portrait of a King
-

- Marco Cadioli – Portrait of a man who has lost everything
Mattia Casalegno (IT, Napoli 1981), artista italiano con residenza a New York, è difficile da inquadrare dal momento che la sua vasta produzione artistica e la sua sensibilità lo vedono impegnato, con voce originale e significativa, nella messa a fuoco dei temi più critici per la nostra umanità e ciò attraverso una molteplicità di media, dalla tecno-performance alla Generative AI Art . Per conoscerlo meglio, più che ricorrere a molte di definizioni, è perciò opportuno partire da due esempi, le sue più recenti presenze sulla scena artistica internazionale.
Qualche settimana fa, nell’immenso Superblue Miami, un parco giochi interattivo saturo di arte, durante la Miami Art Week 2022, grazie alla collaborazione con Meta Open Arts, ha riproposto gli “Aerobanquets RMX”, una esperienza gastronomica multisensoriale liberamente ispirata al “Futurist Cookbook”, il libro futurista di ricette surreali e cene fantastiche pubblicato nel 1932 da Marinetti. Un libro che a ben guardare offre una prospettiva provocatoria e visionaria sul futuro dell’alimentazione, toccando con largo anticipo temi delle società post-capitalistiche.
Per l’Esposizione “Prompt Generations” Mattia Casalegno propone due frame realizzati con tecnologie text-to-image ed utilizzati nella progettazione e realizzazione dell’opera audiovisuale “La Maschera del Tempo”, che lo ha visto collaborare simbioticamente con il sound-artist Maurizio Martuscello (a.k.a. Martrux_m), per la committenza della Fondazione Cini di Venezia.
L’opera, presentata alla fine dello scorso mese di settembre, si propone di valorizzare il “Teatro Verde”, un meraviglioso teatro all’aperto che Katharine Hepburn ebbe a definire “il più bel teatro del mondo”, reinterpretandone la storia, gli spettacoli, il presente e il possibile futuro. Le immagini text-to-image sono servite a definire il drammatico paesaggio post-antropocentrico dal quale riaffiorano, dopo il diluvio universale, le tracce di una civiltà ormai scomparsa e la meravigliosa disposizione della piattaforma esagonale del Teatro Verde e degli spalti.
-

- Mattia Casalegno – La Maschera del Tempo, still from video #1
-

- Mattia Casalegno – La Maschera del Tempo, still from video #2
Pier Giorgio De Pinto (CH/IT, Civitavecchia 1968) è un artista al quale va riconosciuta una sensibilità straordinaria nell’affrontare tematiche logico-filosofiche, geometrico-matematiche e tecnologico-comunicative con una padronanza delle molteplici espressioni artistiche ed una leggerezza – nel senso che Italo Calvino ebbe a dare alla parola – che, a mia conoscenza, ha pochi eguali.
Nelle sue opere, contrassegnate da una ineccepibile perfezione realizzativa, lo spettatore ritrova sempre una caratteristica fondante: la ricerca dell’ordine geometrico della natura come punto di partenza per affrontare nuove esperienze, nuove conoscenze. Un grande interprete, in chiave contemporanea, della lezione galileiana: “Il Libro della natura è scritto nella lingua della matematica, i cui caratteri sono triangoli, cerchi e figure geometriche.”
Per questa esposizione presenta due opere: “Gertrude Stein Tender Buttons” e “Gödel, Escher, Bach: An Eternal Golden Braid”.
“Out of an eye comes research.”, non è solo un piccolo frammento delle poesie automatiche di Geltrud Stein, ma è anche il principio che Pier Giorgio De Pinto fa proprio nel presentare quest’opera. “La ricerca nasce a partire dall’occhio”, quindi la ricerca è il passaggio dal vedere al guardare, dal percepire con gli occhi al soffermarsi a riflettere su ciò che si è percepito. E allora ecco che l’occhio dell’AI risulta essere un occhio straordinariamente potente, che restituisce un ordine di grandezza e di fascinazione che lascia attoniti, l’artista prima, lo spettatore poi.
In “Gödel, Escher, Bach: An Eternal Golden Braid”, Pier Giorgio De Pinto usa il prompt per costruire un’immagine estremamente precisa nella sua strutturazione e fortemente aperta ad una molteplicità di interpretazioni. Azzardo a proporne una, ben sapendo che non è, e non può essere, la sola: se con Geltrud Stein egli affronta il microcosmo, con Kurt Godel, Maurits Cornelis Escher e Johann Sebastian Bach egli affronta il macrocosmo. Una visione cosmogonica del tutto che ci fa ritornare a concetti filosofico ermetico esoterici, profondamente radicati nel nostro sistema cognitivo.
-

- Pier Giorgio De Pinto – Gertrude Stein Tender Buttons
-

- Pier Giorgio De Pinto – Gödel, Escher, Bach: An Eternal Golden Braid
Dogan Erdal (TR, Niğde 1961), figura eclettica di artista, è passato dalla professione di ingegnere meccanico a quella di game designer, per approdare poi all’industria del cinema e dell’animazione dove ha operato in diversi campi come design, animazione, effetti cinematografici, montaggio, programmazione DVD, design di riviste. E’ inoltre un prolifico compositore di musica classica con oltre 900 opere per pianoforte e sinfoniche, oltre che poeta e strumentista.
La sua curiosità e la sua vicinanza alle più avanzate tecnologie lo ha condotto inevitabilmente ad incrociare le nuove frontiere della creatività AI, ed in particolare della Generative AI Art.
Lo stile delle sue opere ci porta automaticamente a collocarlo nell’ambito di un tecno-surrealismo, ma questo è il risultato di una precisa volontà, che per Dogan Erdal è quella di capire e se possibile scardinare attraverso il dialogo testuale la logica delle risposte del Modello AI, proponendo a questo dei prompt “folli”.
Come ebbe a scrivere Honoré de Balzac: “Gli stupidi parlano del passato, i saggi del presente, i folli del futuro.”. Dialogando con la Generative AI Art, Dogan Ardal, intende quindi aprire così uno squarcio sugli scenari che ci riserva un futuro sempre più incerto. In “Beyond Mind”, osserviamo come la scatola cranica degli umanoidi non contenga più la materia grigia. Là dove operavano le sinapsi ora c’è un intricato roviglio di fili e di connessioni. C’è da chiedersi se l’inizio di tutto questo non sia già segnato con il prossimo utilizzo dei Neuralink di Elon Musk. Non meno sconcertante è la visione della seconda opera: “Libido”, nella quale l’ammasso dei corpi privi di ogni tratto umano precipita e si accumula sul fondo, mentre altre figure sembrano divorarle.
-

- Dogan Erdal – Beyond Mind
-

- Dogan Erdal – Libido
Marc Librescu (US, 1959), è artista e illustratore le cui radici affondano nelle sperimentazioni pionieristiche dell’arte digitale. “…da quando ho acquistato il mio primo Mac (un Classic II) nel 1991.”, egli afferma. Ma i suoi processi creativi sono anche legati alla sua formazione, egli infatti ha studiato Fotografia alla School of Visual Arts di New York City.
Questo background risulta subito evidente nel suo lavoro, che spesso incorpora elementi fotografici nella sua produzione artistica realizzata con le applicazioni tex-to-image, che comprende: ritratti, paesaggi, immagini surreali e persino cartoni animati.
Per l’Esposizione “Prompt Generations” presenta due immagini della serie “The Americans Revisited” Midjourney e rielaborate il post-produzione con altri sofisticate applicazioni: Topaz Sharpen AI, Affinity Photo 2, DXO FilmPack 6
“Queste immagini fanno parte di un progetto entusiasmante e stimolante per me, poiché utilizzo l’intelligenza artificiale per creare immagini che includano la figura umana.”
Il fascino che prova Marc Librescu nasce innanzi tutto dalla sfida tecnologica. La Generative AI Art infatti è ancora nelle sue fasi iniziali e cercare di ottenere immagini realistiche di persone è una operazione non sempre semplice e di successo. Ma è soprattutto quando il risultato è soddisfacente che egli si chiede: “Chi è questa gente? Qual è la loro storia?”.
E così, memore che nell’arte contemporanea il pubblico ha un ruolo attivo nel processo di costruzione del significato delle opere d’arte, contribuendo o addirittura completando l’opera con le proprie personali riflessioni, esperienze, opinioni e interpretazioni, egli invita gli spettatori a considerare queste domande e ad interpretare le immagini a modo loro.
-

- Marc Librescu – Couple – Woodvale, New York
-

- Marc Librescu – Train – Fairbrook, New Jersey
Patrick Lichty (US, Akron 1962) è un Media Artist, scrittore, curatore e designer, ma è soprattutto un vulcanico sperimentatore e teorico della Generative AI Art.
Gli obbiettivi della sua ricerca risultano molto precisi: “Il concretismo visivo nei generatori di immagini di apprendimento automatico basati su prompt. La centralità della scrittura nei metodi di creazione. La ricerca degli spazi alternativi, negli spazi latenti di Machine Learning, come forme della scrittura concretizzata.”
Quindi per Patrick Lichty questa forma di imaging non riguarda la creazione artistica, ma la scrittura. La generazione di immagini AI basata su prompt è una concretizzazione della sintassi sotto forma di prompt che il Modello AI decodifica.
Altra osservazione che ho trovato molto interessante è la seguente: “Con la generazione di immagini di machine learning basata su prompt l’algoritmo sta addestrando l’umano ad adattarsi in modo che l’algoritmo stesso possa dare all’umano qualcosa che trova più accettabile, piacevole e così via. In breve, abbiamo l’evoluzione computer-umano, in cui i sistemi tecnocratici neoliberisti programmano, inscrivono ed evolvono esplicitamente la loro estetica e poetica sull’utente.”
Sulla base di questi presupposti egli ha cerca di scrivere dei prompt che diano risultati altamente inaspettati. La casualità, per esempio, gli serve per provocare risultati sorprendenti e quindi per cercare di vedere cosa c’è dietro il sipario, per esplorare i quadranti solitamente invisibili dello spazio latente. Grazie ai suoi profondi legami con il movimento Fluxus, sta anche cercando di vedere se è possibile inserire in questo processo creativo una componente di improvvisazione. In altre parole egli afferma: “Provo a rompere la macchina, a vedere le crepe nel suo senso logico, o in generale a diventare caotico. Questo è ciò che fanno gli artisti.”
Per l’Esposizione “Prompt Generation“ presenta due “Architectures of the Latent Space”, frutto di una ricerca che tende ad escludere dai prompt persone, animali, piante, paesaggi. In modo, come ha coerentemente affermato, da esplorare i residui spazi alternativi e non rappresentativi.
-

- Patrick Lichty – Architectures of the Latent Space (5_3)
-

- Patrick Lichty – Architectures of the Latent Space (6_4)
Sabrina Ratté (CA, Québec city, 1982), artista canadese con importanti presenze in Francia, è una delle voci più significative del panorama dell’Arte Digitale internazionale. Le sue opere video, connotate da uno stile inconfondibile, affrontano temi legati all’architettura, ai biomi, in particolare ai giardini, dove vengono collocate surreali e intriganti sculture digitali.
Le due immagini presentate: “Living fields of psychic presences” n. 1 e n. 2, aprono una finestra sulla sua attuale ricerca, improntata al dialogo con i Modelli AI, da lei inteso come stimolo e fonte di ispirazione, per immaginare un ipotetico futuro post-antropocentrico, nel quale microplastiche, oggetti abbandonati, rifiuti elettronici e micelio andranno a fondersi con la vegetazione e le creature sopravvissute in un apocalittico scenario post-umano.
I processi creativi Text-to-Image sono quindi usati da Sabrina Rattè sono solo punto di partenza, un momento di un dialogo con un’entità che già ora contiene in sé, a saperle decriptare, le indicazioni di un possibile futuro. Successivamente lei intervenire con Photoshop, un altro software molto sofisticato che le consente di definire meglio l’immagine, partendo dalla sua voluta ambiguità. In queste immagini infatti i toni gradevoli sembrano contraddire la drammaticità del paesaggio, ma, come afferma l’artista, essi sono il risultato della frantumazione e della colorazione delle rovine.
-

- Sabrina Rattè – Living fields of psychic presences 1
-

- Sabrina Rattè – Living fields of psychic presences 2
Leggi anche: Prompt Generations #1: “L’Intelligenza Artificiale libera l’immaginazione” | Prompt Generations #2: “L’origine e la storia di una rivoluzione: Open AI” | Prompt Generations #3: “E’ Arte o non è Arte, è Arte o non è Arte, …”
Arte.go: “Prompt Generations”. A Virtual Exhibition of AI Art provided by an Italian Art movement.
“C’e’ una galleria on-line, la arte.go.it, che ha già tempestivamente sfornato “Prompt Generation”, una mostra di artisti che lavorano usando questi sistemi”. di Antonio Riello
Miart a Milano, raddoppiate le gallerie estere: grande vitalità per l’arte contemporanea in città. di Pierluigi Panza
